

Hoy en día se sabe que los datos son los principales activos de una compañía. Tenerlos en cuenta como tales es vital para tomar conciencia sobre la amplia utilización que podemos hacer de ellos. Implementar Data Science hace posible identificar la información necesaria, procesarla y hacer un análisis que permitan elegir la mejor alternativa para tu negocio.
En este artículo descubrirás todo lo que necesitas saber para comprender por qué tu compañía debería incorporar la ciencia de datos.
Data Science: ¿Qué es y para qué se utiliza?
Data Science es un campo multidisciplinario que tiene la finalidad de extraer datos y procesarlos para llegar a las conclusiones correctas a partir de ellos. Su desarrollo surge de la necesidad de acceder a los grandes volúmenes de información que se generan a partir de la actividad online de los usuarios a diario.
En otras palabras, es una forma de interpretar los datos y usarlos para resolver una determinada necesidad. Pero el punto más importante de esta área es su capacidad de analítica predictiva para adelantarse a eventos futuros, una funcionalidad sumamente útil para tomar mejores decisiones de negocio.
Para lograrlo se emplean herramientas de software que utilizan Inteligencia Artificial y algoritmos de Machine Learning. De esta manera es posible conocer las probabilidades de comportamiento de esos datos a partir del análisis como, por ejemplo, los hábitos de consumo de un segmento de clientes. A partir de esta información se pueden predecir fraudes, pedidos de bajas en un servicio, incumplimiento de pagos, entre otras acciones que pueden afectar a una empresa.
¿En qué áreas se puede aplicar Machine Learning en Data Science?
Los softwares que funcionan con esta tecnología tienen la capacidad de aprender automáticamente. Lo único que necesitan es ser provistos inicialmente de datos y partiendo de esa base, puede avanzar con su procesamiento.
Algunas de las implementaciones más exitosas que utilizan las compañías en beneficio de sus modelos de negocio son:
El área de ventas: segmentar la base de contactos, optimizar el margen de ganancias, entre otros aspectos.
Fidelización de clientes: predecir la tasa de abandono y generar estrategias para prevenirlo.
Reducción de costos: detectar posibles casos de fraude, realizar un scoring crediticio y hacer predicciones respecto a la demanda.
¿Cómo incorporar Inteligencia Artificial en Data Science?
Los softwares de Inteligencia Artificial son actualmente muy aplicados por las empresas mediante la implementación de herramientas como:
Chatbots: para mejorar la experiencia de atención al cliente.
Reconocimiento por imágenes: facilita la identificación de los usuarios garantizando la seguridad de los datos.
Análisis de sentimientos: se basa en tratar de comprender las opiniones de los consumidores sobre los servicios o productos que ofrece una empresa.
Las técnicas de Data Science más utilizadas
Existen diferentes técnicas que ayudan a predecir de qué manera se comportará un dato en el corto, mediano o largo plazo. Para saber a cuál en cada caso primero es necesario conocer y comprender entender cada técnica. Las más indicadas para trabajar en Data Science son: Random Forest, XGBoost y Decision Trees.
Por otra parte, los dos lenguajes de programación más comunes son Python, que es el que ha presentado una mayor adopción para procesar los datos, y R, que fue creado por estadísticos. A su vez, dentro de cada lenguaje hay diferentes librerías que se pueden aplicar para codificar en función de ella.
Cómo mejorar la toma de decisiones con Data Science: paso a paso
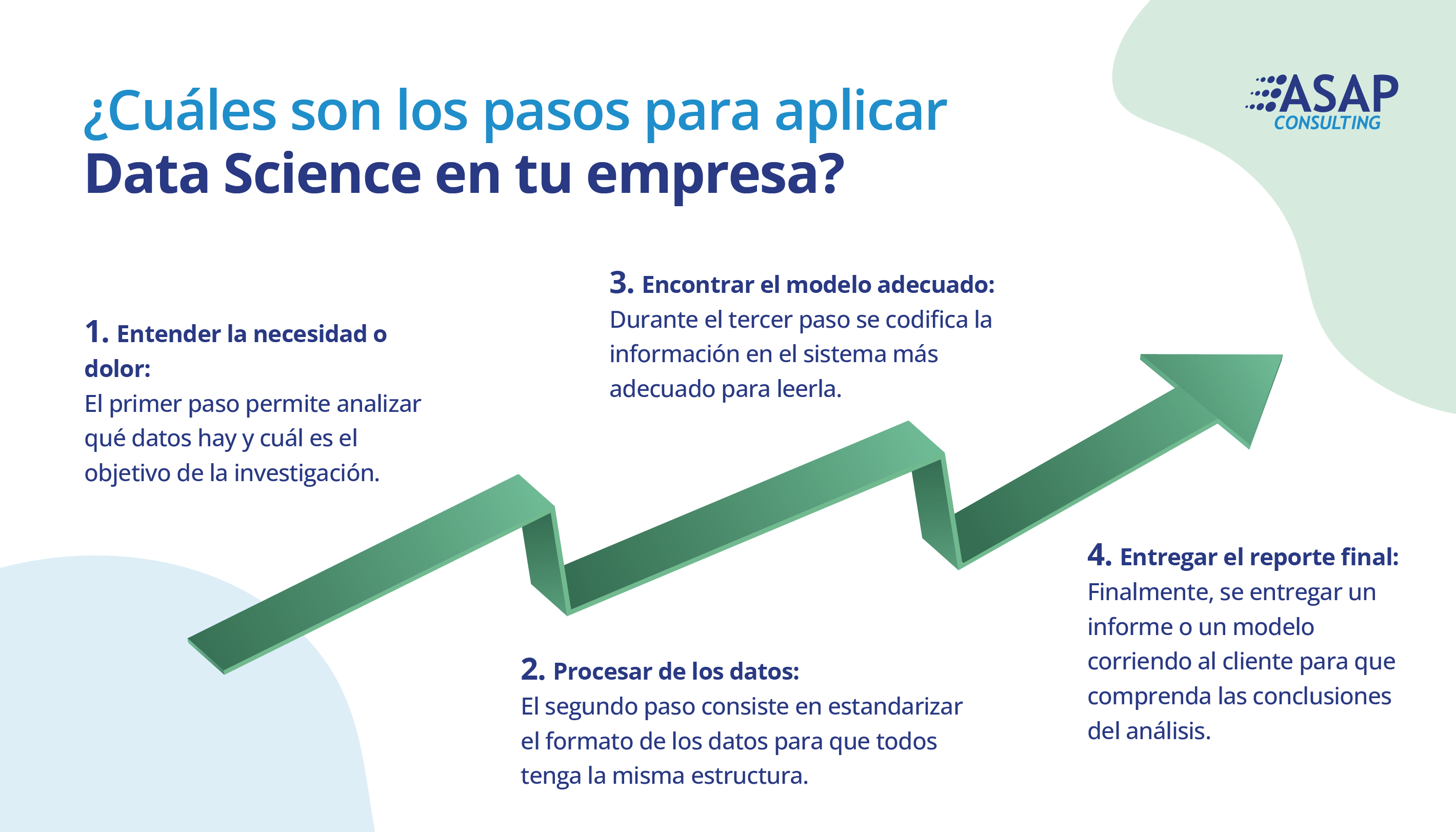
1. Comprender la necesidad del cliente
El primer paso consiste en analizar cuáles son los pain points del cliente, es decir comprender sus necesidades. A partir de este conocimiento es posible detectar qué datos hay disponibles para su procesamiento.
2. Pre procesamiento de los datos
La segunda instancia para la implementación de Data Science es el pre procesamiento de los datos. Una vez identificada la información a relevar, es momento de ordenarlos aplicando alguno de los softwares ya mencionados, como Random Forest, XGBoost o Decision Tree.
Hallar los datos indicados es, probablemente, la parte del proceso que más tiempo conlleva porque implica estandarizarlos para su posterior tratamiento.
En este punto también es posible detectar si falta algún dato y en caso de que no se encuentre ninguno hay dos opciones: solicitarle esta tarea al cliente u ofrecerle ese servicio. La segunda alternativa es más recomendable porque se recaban los datos de la manera o en el formato en que se van a procesar.
3. Elegir un modelo
El tercer paso consiste en encontrar el modelo que se adecúe mejor para codificar los datos y expresarlos, por ejemplo, en un gráfico. En este punto se puede elegir entre dos modelos: de clasificación o de regresión. A su vez, el entrenamiento del software de Machine Learning puede ser supervisado o no supervisado.
4. Entrega
La entrega puede ser un informe o un modelo corriendo. En el segundo caso la información queda plasmada en un software, donde el cliente puede ver los datos en un dashboard. No obstante, también puede solicitar la visualización desde otra plataforma, por ejemplo en un CRM.
ASAP: Data Science as a service
En ASAP Consulting contamos con un equipo experimentado en la implementación de ciencia de datos para brindar a nuestros clientes la oportunidad de optimizar sus procesos de toma de decisiones.
Las empresas basadas en datos tienen su ciclo organizado y estructurado, un trabajo que requiere inversión en personas, cultura, tecnologías y procesos. ¿Necesitas apoyo para lograrlo? ¡Contáctanos!